Cot Without Prompting
Can Pre-Trained Language Models Reason Without Complex Prompts?
Recent research indicates that pre-trained language models (LLMs) have the inherent ability to engage in Chain of Thought (CoT) reasoning without the need for complex prompt engineering. This finding, stemming from a paper titled “Chain of Thought Prompting Elicits Reasoning in Large Language Models,” explores an innovative decoding strategy that could democratize sophisticated language model capabilities. Here is a link to the file from Google Research on arxiv
The Shift From Greedy to CoT Decoding
Traditional decoding methods, like greedy decoding, often fall short when it comes to eliciting CoT reasoning from LLMs. The new approach, termed CoT-decoding, diverts from this path and leverages alternative tokens in the top-k predictions to uncover reasoning patterns that would otherwise remain hidden. This strategy not only sidesteps the need for complex prompts but could potentially increase unsupervised performance, making advanced reasoning accessible without the need for fine-tuning.
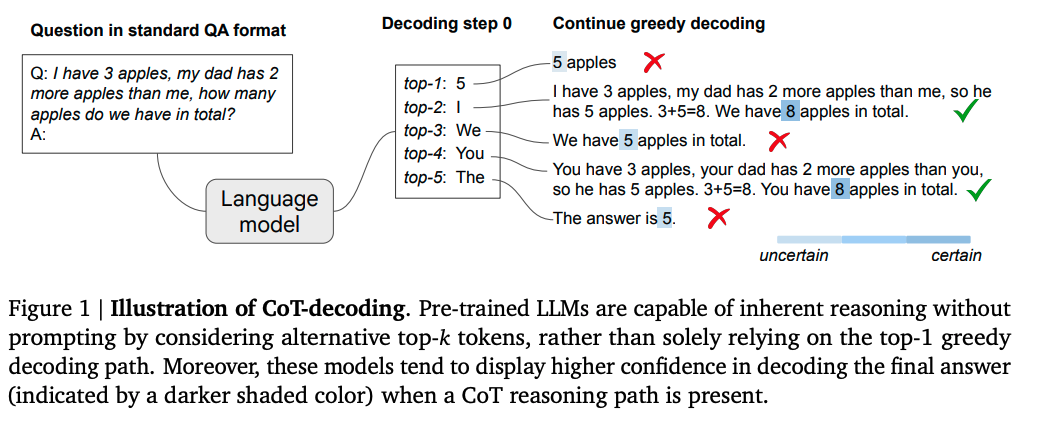
How It Works
The method involves using a standard QA format to prompt the language model. Instead of relying solely on the top-1 greedy path, the CoT-decoding examines various top-k alternatives, which has been shown to bring forth natural CoT reasoning patterns.

Insights and Probability Assessments
One of the key components of CoT-decoding is an equation used to calculate the corresponding probability for each decoding path, which favors tokens with the highest post-softmax probabilities.
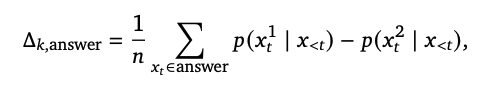
A noteworthy heuristic from the research is the preference for longer decoding paths, which often contain CoTs, especially in math problems. However, it’s been observed that ensembling decoding paths frequently results in incorrect answers. To counter this, a weighted aggregation method is used to determine the most likely answer.
Empirical Results
The research demonstrates a notable improvement in accuracy when CoT decoding is employed, even without fine-tuning.
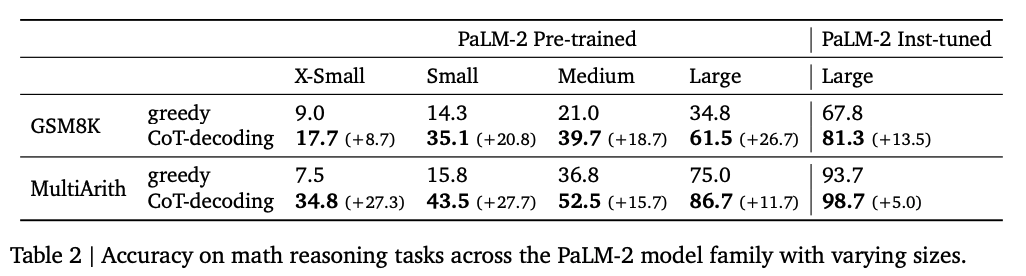
Implications and Limitations
While the results are promising, CoT paths are less prevalent in tasks that deviate from the model’s training distribution. The research suggests that while few-shot learning or fine-tuning could mitigate this, it moves away from the paper’s aim of avoiding such strategies.
Final Thoughts
The paper highlights the significance of the initial word predicted by the model, as the right choice can naturally lead to a CoT path. This underlines the importance of the pretraining dataset and suggests that tasks outside the domain might not naturally induce CoT paths.
This groundbreaking research presents a potential shift in how we can harness the reasoning capabilities of LLMs, making advanced model reasoning more accessible and less dependent on elaborate prompting strategies or model fine-tuning.